
Vista dall’esterno, una rete neurale artificiale è un software eseguito da un computer. La particolarità rispetto al resto dei programmi è la sua capacità di apprendere quali sono le relazioni tra i dati in ingresso e i dati in uscita (i risultati), questo attraverso una struttura logica di base che non cambia al variare dei dati e delle relazioni, ma si adatta.
Il nome rete neurale viene dal paragone con quella del nostro cervello. La sua struttura prevede una serie di punti, detti nodi, connessi tra loro, che ricevono un valore numerico da altri nodi, lo aumentano o diminuiscono e restituiscono il risultato a nodi diversi da quelli da cui l’hanno ricevuto. In modo simile, nel nostro cervello i neuroni ricevono un impulso elettrico da una serie di neuroni e a loro volta ritrasmettono o meno questo impulso elettrico ad altri neuroni. Detta così, un neurone non sembra un oggetto molto intelligente. Gli arrivano delle piccole scosse e tutto quello che fa è ritrasmetterle o meno ad altri neuroni. Come può tutta questa corrente che ci gira nella testa trasformarsi nelle cose così complesse che riusciamo a fare? Il segreto sta nella quantità. Se ad esempio avessimo 100 neuroni, non solo non saremmo molto intelligenti, ma, per come siamo fatti, non sarebbero sufficienti nemmeno per restare in vita (tuttavia ci sono animali che non hanno alcun neurone, come ad esempio le spugne). E se ne avessimo 1000? Non farebbe molta differenza, pensate che una medusa ne ha circa 6000 e fa parte della categoria di fauna con la più bassa capacità cerebrale. Un topo ne ha già circa 70 milioni e noi esseri umani arriviamo a ben 86 miliardi. Ma come fa la quantità a trasformare un processo così basilare e banale nelle sorprendenti abilità che possediamo? Per arrivare alla risposta analizziamo una rete artificiale.
La rete di neuroni artificiale
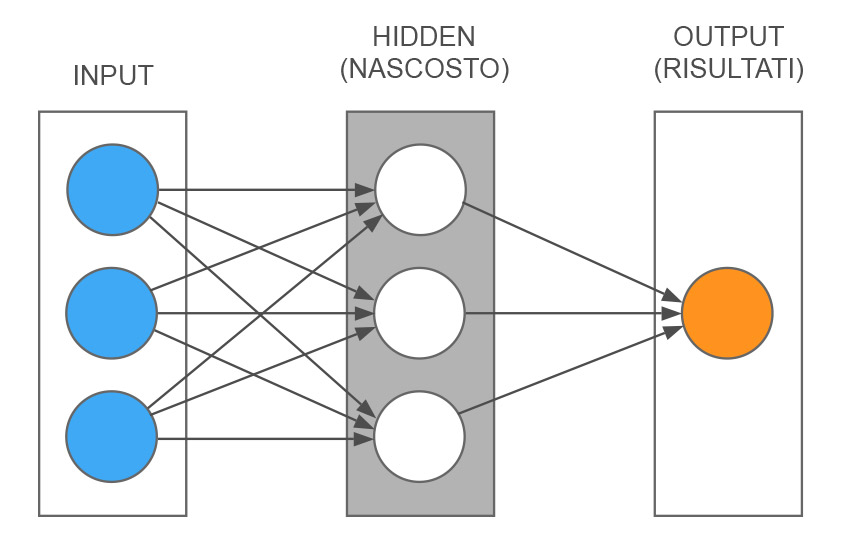
Schema di una rete neurale artificiale semplificata
Iniziamo a schematizzare un esempio di rete neurale molto semplice per capirne il meccanismo più nel dettaglio. Come vedete nella figura, abbiamo tre livelli. Uno di input dove in questo caso ci sono tre nodi (cerchi azzurri), questi tre nodi rappresentano tre informazioni in ingresso. Un livello centrale detto nascosto, per il fatto che non comunica direttamente con l’esterno (cerchi bianchi). E un livello a destra che rappresenta i risultati, in questo caso fatto da un solo nodo (cerchio arancione). Le linee grigie mostrano le connessioni tra i vari nodi. Il modo più semplice per spiegarne il funzionamento è con un esempio.
Un esempio di previsione meteo
Usiamo un modello di previsioni meteo estremamente semplificato. Supponiamo di voler capire se fra un’ora pioverà o meno, basandoci su tre semplici fattori: 1) La quantità di nuvole in cielo, 2) La velocità del vento, 3) L’eventuale quantità di pioggia in questo momento. I nostri tre input saranno dei numeri decimali che possono andare da 0 a 1. Ad esempio per il primo fattore, la quantità di nuvole, avremo uno 0 se non c’è alcuna nuvola in cielo, uno 0,5 se le aree annuvolate e quelle serene sono equivalenti, fino ad arrivare a 1 nel caso in cui tutto il cielo è coperto di nuvole. Quindi possiamo vedere il nostro valore di nuvolosità come la percentuale di cielo coperta da nuvole. Allo stesso modo faremo per gli altri due fattori, quindi il fattore di vento, che sarà 0 nel caso di assenza totale fino ad arrivare ad 1 nel caso di velocità massima (verrà definita a priori una velocità massima a cui assegnare 1 a seconda della zona geografica in cui stiamo facendo le previsioni). Infine assegniamo il valore della quantità di pioggia, 0 nel caso di totale assenza fino a 1 per l’intensità massima. Per tenere l’esempio più semplice possibile abbiamo un solo risultato e lo chiamiamo Piove.
Il livello nascosto
Adesso che abbiamo deciso quali sono gli ingressi e le uscite della nostra rete neurale, possiamo procedere a spiegare cosa fa questo fantomatico livello intermedio. Come potete vedere dalla figura, ognuno dei pallini bianchi (che simboleggiano i neuroni) riceve tutti e tre gli input. Quindi ognuno di questi nodi riceve tre numeri compresi tra 0 e 1. La prima cosa che fa è assegnare un “peso” ad ognuno di questi tre valori. Questo significa che definisce una percentuale per ognuno degli input. Poi calcola queste percentuali e le somma. Vediamo un esempio.
Prendiamo questi tre input: Nuvole = 0,8 ; Vento = 0,1 ; Pioggia = 0,3. Siamo in una situazione di cielo molto nuvoloso, con pochissimo vento e un po’ di pioggia. Il primo nodo decide di dare alla nuvolosità un peso del 35%, al vento un peso del 52% e alla pioggia un peso del 2%. Quindi i valori di input di questo nodo diventeranno: 0,8 x 0,35 = 0,28 ; 0,1 x 0,52 = 0,052 ; 0,3 x 0,02 = 0,006. Dopo aver fatto questi calcoli, il nodo somma i tre risultati: 0,28 + 0,052 + 0,006 = 0.338. Immagino che vi stiate ponendo due domande, dov’è andato a prendere quelle percentuali per calcolare il peso di ogni input? Per quale motivo fa questa cosa? Iniziamo a rispondere alla prima, per la seconda la risposta arriverà più avanti. Queste percentuali sono a caso. Bene, voi direte, già il tutto sembrava poco intelligente prima, adesso che si inventa i numeri sembra proprio senza senso. In realtà possiamo affermare che a questo punto del processo il nostro sistema è ignorante, perché non ha ancora utilizzato l’intelligenza per imparare, ma lo farà.
Il prossimo passaggio consiste nel definire una soglia, cioè un valore minimo oltre il quale questa informazione andrà avanti oppure no. In questo caso ad esempio possiamo definire che se il risultato del calcolo di un nodo supera 1,5 allora il segnale viene trasmesso oltre, altrimenti si ferma lì. Anche per questo valore non sappiamo a priori qual è quello corretto per ogni nodo, quindi potremmo impostare un numero qualsiasi. Tuttavia in questo caso ho introdotto il risultato di un mio ragionamento nella rete neurale, scegliendo la media della somma degli input. Nel nostro esempio la somma dei tre input può andare da 0 (quando sono tutti zero) a 3 (quando sono tutti uno). Ho fatto questo per mostrare come sia possibile far partire una rete neurale con dei parametri che hanno già un senso, quindi figli di una conoscenza e un ragionamento esterni alla rete neurale. Il vantaggio di fare questo è semplicemente quello di diminuire il tempo che la rete impiegherà per arrivare ai risultati, ma non è assolutamente una cosa necessaria. Per ottenere matematicamente il prosieguo o meno dell’informazione, introduciamo una funzione matematica che genera il valore 0 se il risultato del calcolo precedente è minore di 1,5 oppure genera un 1 nel caso il risultato è maggiore di questa soglia. Quindi dal nodo uscirà uno 0 o un 1.
I risultati del pensiero artificiale
Ora siamo all’ultimo livello, quello dei risultati. Ogni nodo centrale è collegato a quello del risultato, che abbiamo chiamato Piove. Questo nodo riceve uno 0 o un 1 da tutti i nodi centrali, esattamente come prima, applica un peso ad ogni valore in arrivo e ha un valore di soglia, sotto al quale la stessa funzione matematica di prima genererà uno 0 e sopra genererà un 1. Quindi niente di diverso rispetto al livello precedente. Eravamo rimasti che il primo nodo del livello centrale aveva calcolato il valore 0,338, che è minore di 1,5, quindi ha trasmesso al nodo dei risultati uno 0. Pertanto quest’ultimo ha ricevuto uno 0 dal primo nodo centrale, diciamo che gli applica un peso del 71%, quindi ottiene 0 x 0.71 = 0. Allo stesso modo ha ricevuto i valori dagli altri due nodi centrali, quindi ipotizziamo gli altri valori con il loro peso e facciamo la stessa somma che abbiamo fatto per i nodi centrali: 0 x 0,71 + 1 x 0,27 + 1 x 0,95 = 1,22. In questo caso, senza fare nessun ragionamento, decidiamo che la soglia di questo nodo è 2, quindi essendo 1,22 minore di 2 la nostra funzione matematica genererà uno 0. Cosa significa che il nodo del risultato Piove è uguale a zero? Decidiamo noi cosa significa, e diciamo che se il valore è 0 allora tra un ora non pioverà, mentre se è 1 significa che tra un ora pioverà. In questo esempio la nostra rete neurale ci ha detto che la previsione è che non pioverà. Se il processo finisse qui avrebbe lo stesso valore di lanciare una moneta e decidere che testa significa che pioverà e croce no, perciò adesso dobbiamo rendere la nostra rete neurale capace di imparare.
Il machine learning (l’apprendimento della macchina)
Per permettere alla rete neurale di apprendere quali relazioni ci sono tra le informazioni in ingresso e i risultati, abbiamo bisogno di dati reali. Nel nostro esempio dobbiamo raccogliere i dati della nuvolosità, della velocità del vento e dell’intensità della pioggia per un certo periodo di tempo. Con queste informazioni abbiamo sia gli input che i risultati, perché, se rileviamo i dati ogni ora, sappiamo che l’intensità di pioggia ad un certo orario è quello che avrei dovuto prevedere un’ora prima, quindi vado a correlarlo ai tre parametri dell’ora precedente. Nel nostro caso molto semplice il risultato non è nemmeno l’intensità, ma semplicemente la presenza o l’assenza di pioggia. Una volta che ho un buon numero di dati (ovviamente più è grande e più saranno attendibili le previsioni), applico alla rete neurale quella che viene chiamata retropropagazione dell’errore.
Detto in altre parole, non è altro che una sorta di apprendimento per tentativi. Quando la rete lavora sulla serie di dati storici, può fare un confronto tra i risultati da lei ottenuti e quelli reali. In generale tra i due valori ci sarà una differenza, quindi un errore. Lo scopo dell’apprendimento è lo stesso per un essere umano, smettere di commettere errori, o meglio, ridurli il più possibile. Nel nostro esempio molto semplificato la rete neurale potrebbe calcolare uno 0 quando il risultato corretto doveva essere un 1, quindi assenza di pioggia quando in realtà ha piovuto (e viceversa). Ipotizziamo che su 100 misurazioni reali, in 30 casi il risultato è corretto, mentre nei restanti 70 è sbagliato. La rete neurale può modificare i parametri che abbiamo visto prima per ridurre la percentuale di errori: il peso degli input e la soglia che determina se l’uscita dal nodo è 0 o 1.
Come ottimizzare i parametri
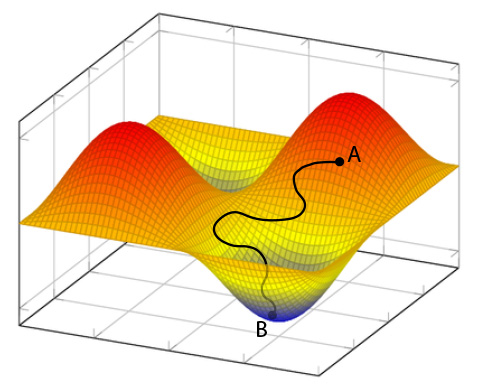
Esempio di funzione che rappresenta l’errore del risultato in relazione ai pesi e alle soglie, cioè ai parametri che la rete neurale può variare.
Una prima ipotesi è quella di continuare a modificare questi valori per ogni nodo in modo casuale finché l’errore scende sotto un certo livello che riteniamo accettabile, così facendo avremmo una rete neurale che ha imparato quali sono le correlazioni tra input e risultati. Questo sistema forse potrebbe anche funzionare per il nostro esempio composto da una manciata di neuroni, ma pensate ad una rete fatta da centinaia di migliaia di nodi, sicuramente non ci basterebbe una vita intera per vedere il risultato, non solo, probabilmente andrebbe oltre la durata dell’universo dalla sua nascita ad oggi. Allora dobbiamo pensare a metodi più furbi per trovare i parametri corretti. Possiamo usare una funzione matematica che contiene i nostri parametri e rappresenta il nostro errore, e quello che dobbiamo fare è trovare dove è minima (e quindi dove l’errore è minimo). Nell’immagine vediamo un esempio di funzione dell’errore in due variabili, quindi una superficie curva con dei massimi e dei minimi (cime ed avvallamenti). Quello che dobbiamo fare è modificare i nostri parametri per arrivare sul fondo dell’avvallamento più basso. In questo caso ipotizziamo che con i parametri iniziali, che causano un errore del 70%, siamo nel punto A. Dobbiamo trovare la strada che nel minor tempo possibile ci faccia arrivare al punto B, dove troviamo i parametri che danno l’errore minimo e rendono la nostra rete capace di fare questa previsione meteo. Per fare questo ci sono metodi matematici molto efficaci, come quello chiamato discesa stocastica del gradiente. Comprendere questi metodi implica un approfondimento matematico corposo e lo scopo di questo post è quello di spiegare il concetto generale. Ho messo il link di Wikipedia per i lettori più curiosi e caparbi che desiderano addentrarsi nell’argomento.
Reti più complesse
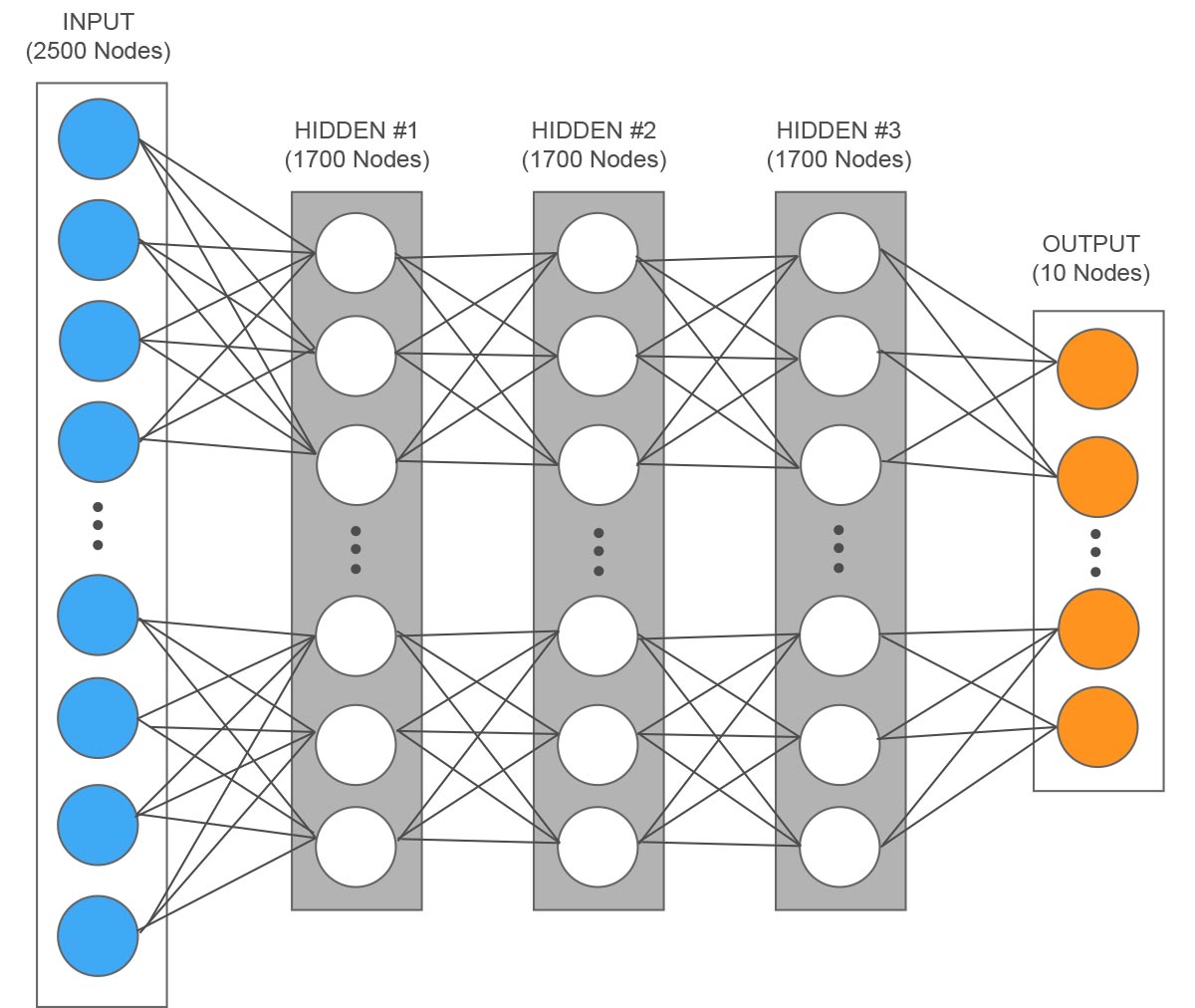
Esempio di una rete per il riconoscimento di cifre scritte a mano con una risoluzione di 50×50 pixel, ogni input rappresenta un pixel.
Adesso la nostra rete ha i parametri corretti, quindi ha imparato quali sono le relazioni tra gli input e i risultati ed è in grado di prevedere se tra un’ora pioverà con un errore contenuto. Questo esempio è estremamente semplificato, in realtà le reti neurali possono gestire un numero di input molto più elevato e anche i risultati possono essere formati da più neuroni. Il livello intermedio può essere composto da più livelli, dove ognuno fa una parte del lavoro e passa il risultato parziale al livello successivo. Facciamo l’esempio di una rete che riconosce i numeri scritti a mano, diciamo dove una singola cifra è un’immagine composta da 50 x 50 pixel, avrebbe quindi 50 x 50 = 2500 valori in input. Ipotizziamo tre livelli intermedi composti ognuno da 1700 neuroni e 10 per i risultati (le dieci possibili cifre da 0 a 9), sarebbero in totale 5110 neuroni. Proviamo a calcolare quanti parametri ci sarebbero da ottimizzare con ogni neurone di un livello connesso a tutti i neuroni del livello precedente: 1700 x 2500 (pesi) + 1700 (soglie) + 1700 x 1700 (pesi) + 1700 (soglie) + 1700 x 1700 (pesi) + 1700 (soglie) + 10 x 1700 (pesi) + 10 (soglie) = 10 milioni di parametri circa. Un ultimo punto da rimarcare è che oltre all’aumento dei neuroni e delle connessioni, le reti neurali artificiali possono lavorare insieme ad altri algoritmi, creando un sistema ibrido più efficiente.
Perché la dimensione fa la forza
Torniamo un attimo alla domanda che ci siamo posti all’inizio. Adesso che abbiamo un’idea del principio di funzionamento di una rete neurale, possiamo anche intuire perché un numero di neuroni maggiore comporta capacità maggiori. In realtà dovremmo parlare anche di numero di connessioni. Perché grazie a loro è possibile avere mix anche molto complessi di input e quindi la possibilità di manipolare in modo più raffinato ciò che entra in un neurone. In sostanza dobbiamo pensare che un neurone fa un’operazione estremamente semplice, quindi se vogliamo ottenere una capacità complessa, la dobbiamo suddividere in un certo numero di operazioni elementari, che, combinate insieme, riusciranno a dare il risultato. Se ho tanti valori in ingresso, come nell’esempio dell’immagine del numero scritto a mano, per poterli gestire tutti e non perdere informazioni, il numero di neuroni deve essere elevato. Proviamo ad esagerare e mettere un solo neurone nel livello intermedio, gli arriveranno tutte insieme le informazioni dei 2500 pixel. Lui potrà solo variare i loro pesi prima di sommarle tutte, in questo modo però avrà solo un valore che sarà una sorta di media di tutti i singoli valori che non dice proprio nulla sull’immagine. Se invece ho più neuroni, il primo potrà dare più peso solo a certi pixel e mandare avanti quell’informazione, il secondo ad altri, e così via. In questo modo l’informazione non si perde e viene sempre più elaborata ad ogni passaggio fino ad arrivare all’ultimo livello, quello dei risultati, dove il neurone corrispondente alla cifra riconosciuta farà uscire il valore 1. Questa suddivisione di compiti tra neuroni viene ottenuta con la fase di apprendimento e la relativa ottimizzazione dei parametri come abbiamo visto nel paragrafo precedente.
Mancanza di intelligenza o di apprendimento?
Facciamo questo esempio sul cervello umano. Siete andati all’estero, in un paese del quale non conoscete assolutamente la lingua. Una persona vi si avvicina e vi parla in questa lingua, il vostro cervello elabora tutte le informazioni sonore ricevute dalle orecchie, ogni neurone viene o meno attivato dall’insieme di impulsi elettrici e a seconda della soglia manda avanti o meno l’informazione ai neuroni successivi e così fino ai risultati. Ma i risultati non avranno senso, saranno solo un guazzabuglio di suoni sconosciuti, sebbene il vostro cervello abbia fatto lo stesso lavoro che fa sempre. La differenza rispetto a quando ascoltiamo un dialogo in una lingua conosciuta è che in questo caso è mancata la parte di apprendimento, dove tutti i parametri vengono settati per elaborare gli input e dare un risultato utile. Anche in questo caso tutta l’informazione proveniente dalla persona che vi parlava è andata persa, ma al contrario dell’esempio del singolo neurone, non poteva elaborare da solo le informazioni di 2500 pixel (mancanza di intelligenza), in questa situazione il numero di neuroni sarebbe stato sufficiente, ma è mancata la fase precedente di apprendimento.
Nel prossimo post parleremo di quali risultati concreti si possono ottenere con una rete neurale artificiale e delle sue principali applicazioni pratiche con gli enormi benefici che porta.